모바일은 화면을 돌려 가로화면으로 보시는 게 읽으시기 편할 수 있습니다. 돌려서 보시는 걸 추천드릴게요!!

💰 ARDL 모델을 사용한 소비자물가지수 영향 지표 분석
💰 연구주제 선정 배경
코로나의 엔데믹을 기점으로 물가의 상승세가 지속되고 있습니다. 이는, 미국이 팬데믹 동안 증가시킨 통화량을 다시 줄이기 위해 금리를 인상시킨 것이 가장 큰 이유인 것으로 보입니다. 또한, 주요 수출국인 우리나라의 경제는 무역 성적에 의해 크게 좌우됩니다. 하지만 한국무역협회에 따르면, 지난해 우리나라 무역수지 순위는 1년 만에 18위에서 198위로 떨어졌습니다. 전 세계적으로 무역수지가 감소하는 추세지만, 특히 우리나라의 순위가 급격히 하락한 원인으로는 우크라이나-러시아 전쟁에 의한 에너지 공급망 위기 및 반도체 수출량 감소가 손꼽힙니다. 그 영향으로, 산업통상자원부가 발표한 4월 수출입 동향에서 우리나라의 수출 성적은 7개월 연속 감소세를 이어갔으며 14개월 연속으로 무역수지 적자를 기록하게 되었습니다. 이러한 상황으로 빚어진 물가 상승이 지속되고 있기에, 소비자가 느끼는 물가에 상대적으로 직접적인 영향을 주는 경제변수를 알아보고자 본 프로젝트를 기획하였습니다.
💰 변수설명
☑️ 종속변수 (2014.01 ~ 2023.03 월간 데이터)
• 소비자물가지수 CPI
☑️ 독립변수 (2014.01 ~ 2023.03 월간 데이터)
• 경상수지, 상품수지, 서비스수지, 자본수지, 무역수지
• 유가, 환율, 코스피지수, 기준금리, 코픽스금리
• 주택매매가격, 실업률, 코로나 확진자 수, 우-러 전쟁 여부
우리나라의 경제를 지탱하는 수요 수지들과, 외국의 경제적 의사결정에 의해 정해지는 경제 변수 및 국내 경제 변수를 채택하였습니다. 이를 통해, 종속변수인 CPI에 영향을 주는 요인을 다양한 각도에서 분석하고자 하였습니다. 이후 .ts( ) 함수를 사용해 각 변수를 시계열 데이터로 변환하였습니다.
💰 자료 분석 과정
☑️ 시각화를 통한 월별 변수 추세 확인
분석을 위해 수집한 데이터는 시계열 자료이기 때문에, 시간에 따른 추세를 통해 변수 별 분산을 파악하였습니다. 아래 <그림 1>을 보면 선정한 변수 중 분산이 증가하는 변수가 있기 때문에 로그 변환을 통해 데이터의 분산을 줄이기로 결정하였습니다.

이를 위해 로그변환한 변수는 [소비자물가지수, 유가, 환율, 코스피지수, 코픽스금리, 주택매매가, 실업률] 입니다.
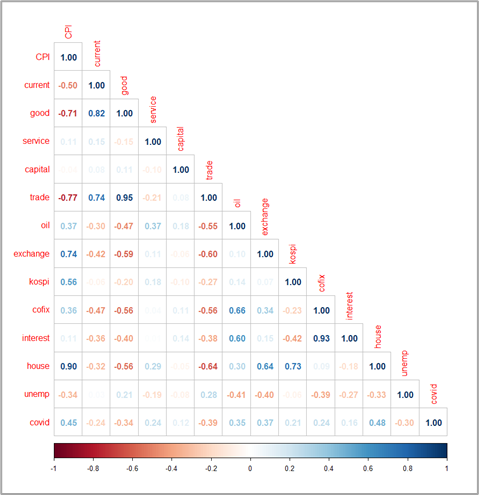
☑️ 변수 간 상관계수 확인
독립변수 간 상관관계가 크다면 다중공선성 문제가 발생할 것입니다. 따라서 상관관계를 분석하여 높은 상관계수를 가지는 변수 쌍을 추출하고, 해당 변수 쌍에서 종속변수와의 상관계수가 낮은 독립변수를 제거하였습니다. 상관계수 0.8을 기준으로 분석 결과 높은 상관관계를 가지는 변수 쌍과 상관계수 아래와 같았으며, 이 중에서 [경상수지, 상품수지, 기준금리]를 제거하였습니다.
• 상품수지 ~ 경상수지 : 0.82
• 무역수지 ~ 상품수지 : 0.95
• 기준금리 ~ 코픽스금리 : 0.93
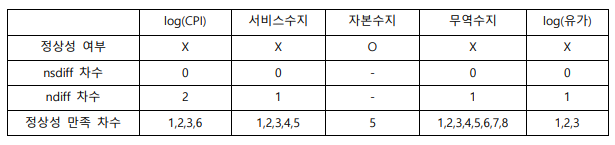
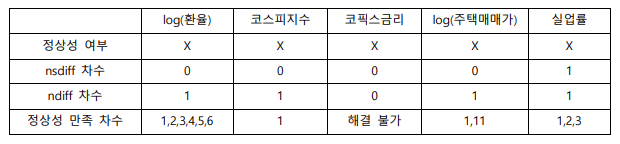
☑️ 시계열의 정상성 검정
데이터에 추세가 있는 경우, 변수 차분 없이 회귀분석을 진행하면 허구적 회귀문제가 발생할 수 있습니다. 추세가 눈에 보이는 확정적 추세라면 시간 더미변수를 사용함으로써 해결될 수 있지만, 확률적 추세라면 차분과 과거값을 사용한 적합이 필수적입니다. 이에, 각 변수에 대한 adf 테스트를 진행하여 확률적 추세의 유무를 파악하고, 변수 변환을 진행하였습니다. 그 결과는 아래 <표 1,2>에 정리해 두었습니다.
☑️ 모델 적합 및 최종 모형 선정
정상성 검정 후, nsdiff 함수 및 ndiff 함수의 리턴값을 근거로 해당 변수를 변환하였습니다. 변환한 모든 변수를 포함한 ARDL 모델을 시작으로 변수를 제거하면서 최적의 모델을 구축하였습니다. 이를 위해 모델 내 변수의 p-value 값을 토대로 변수의 유의성을 검정하였으며, 자기상관을 해결하기 위해 변수의 과거값을 사용하였습니다.
다만 ndiff 함수의 결과값으로 차분한 변수들을 사용하여 구축한 모델은 주로 8, 9, 10, 11차 자기상관을 줄이지 못하였습니다. 이 문제를 해결하기 위해서, 정상성을 만족시키는 차수에 한해 각 변수의 추가 차분을 진행하였으며 추가적으로 월별 더미변수와 시간 더미변수도 추가해 모델을 적합하였습니다.
모델 구축 후 각 변수의 유의성, Adjusted R-squared, ACF, AIC, Box-Pierce Test 결과를 기반으로 최적의 모델을 선정하였습니다. 또한 residual plot을 통해 잔차의 등분산성, 선형성, 정규성을 검증하였으며, 마지막으로는 최종 모델에 사용한 변수들의 상관관계를 분석하여 다중공선성 문제를 다시 한번 방지하였습니다.
💰 최종모형
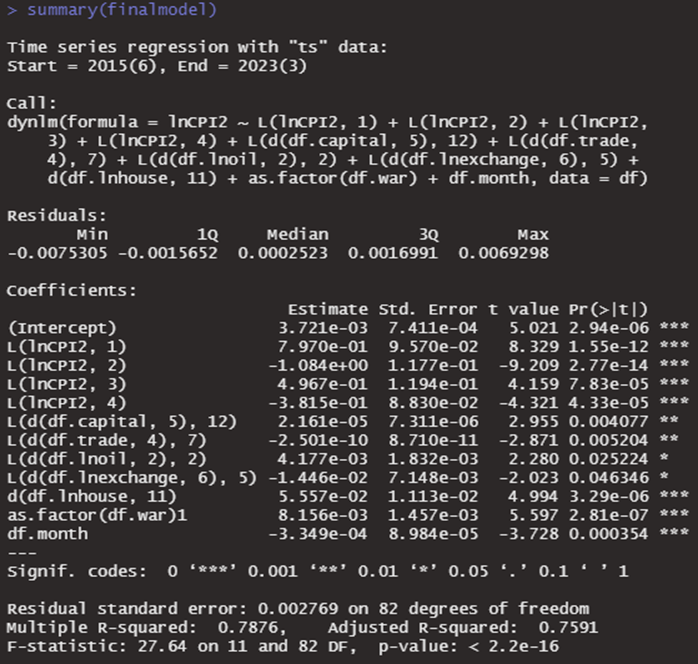
Adjusted R-squared를 통해 모델이 종속변수를 76%가량 설명하는 것을 파악하였습니다. 또한 각 변수의 유의확률이 모두 0.05 보다 작기 때문에 유의하다고 판단하였습니다. 이어서 각 변수가 모델에 미치는 영향을 확인하기 위해 estimate을 살펴보았습니다.
☑️ 모델 해석
• 해당 모델의 종속변수는 CPI 지수를 로그변환한 뒤 2차 차분해준 값입니다. 즉, 본 모델에 있어 종속변수의 해석은 2달전 CPI와 현재 CPI의 차이의 증가율(%)로 해석해줍니다. 앞으로의 모형 해석에서, 종속변수는 lnCPI2 로 칭합니다.
• 1) L(lnCPI2, 1), L(lnCPI2, 2), L(lnCPI2, 3), L(lnCPI2, 4) 해석
- lnCPI2의 한달 전 값이 100% 증가하면 현재 lnCPI2는 0.8%p 증가합니다.
- lnCPI2의 두달 전 값이 100% 증가하면 현재 lnCPI2는 1.1%p 감소합니다.
- lnCPI2의 세달 전 값이 100% 증가하면 현재 lnCPI2는 0.5%p 증가합니다.
- lnCPI2의 네달 전 값이 100% 증가하면 현재 lnCPI2는 0.4%p 감소합니다.
• 2) L(d(df.capital, 5), 12) 해석
현재 lnCPI2값은 작년 동월 자본수지와 작년 동월 대비 5달 전 자본수지의 차이에 의해 영향을 받습니다. 이 차이가 1증가하면 lnCPI2는 0.00002%p 증가합니다. 예를 들어, 지금이 12 월이라고 가정한다면 현재의 소비자물가지수는 작년 7월과 12월의 자본수지의 차이에 의해 영향을 받습니다.
• 3) L(d(df.trade, 4), 7) 해석
현재 lnCPI2값은 7달 전 월의 무역수지와 11달 전 무역수지의 차이에 의해 영향을 받습니다. 이 차이가 1 증가하면 lnCPI2는 2.5 * e-10 %p 감소합니다.
• 4) L(d(df.lnoil, 2), 2) 해석
현재 lnCPI2값은 2달 전 월의 유가와 4달 전 유가의 차이에 의해 영향을 받습니다. 이 차이가 100% 증가하면 lnCPI2는 0.004%p 증가합니다.
• 5) L(d(df.lnexchange, 6), 5) 해석
현재 lnCPI2값은 5달 전 월의 환율과 11달 전 환율의 차이에 의해 영향을 받습니다. 이 차이가 100% 증가 하면 lnCPI2는 0.01%p 감소합니다.
• 6) d(df.lnhouse, 11) 해석
현재 lnCPI2값은 현재 월의 주택매매가와 11달 전 주택매매가의 차이에 의해 영향을 받습니다. 이 차이가 100% 증가하면 lnCPI2는 0.056 %p 증가합니다.
• 7) as.factor(df.war) 해석
전쟁이 있는 경우, 없는 경우에 비해 lnCPI2는 0.008 %p 증가합니다.
모델 해석을 통해 각 경제적 변수의 동향에 따라서 CPI 값이 영향을 받음을 확인하였습니다. 특히 무역수지, 환율, 주택매매가는 현재 월 대비 11달 전의 값이 해당 지표들의 차분 값을 구하는 데에 공통적으로 관여하였습니다. 이를 기반으로, 세 경제적 변수에는 어느 정도의 계절성이 있음을 알 수 있었습니다. 또한 우-러 전쟁의 영향이 꽤나 크게 나타났고, 코로나 확진자 수는 유의미하지 않았습니다.
☑️ Residual plot
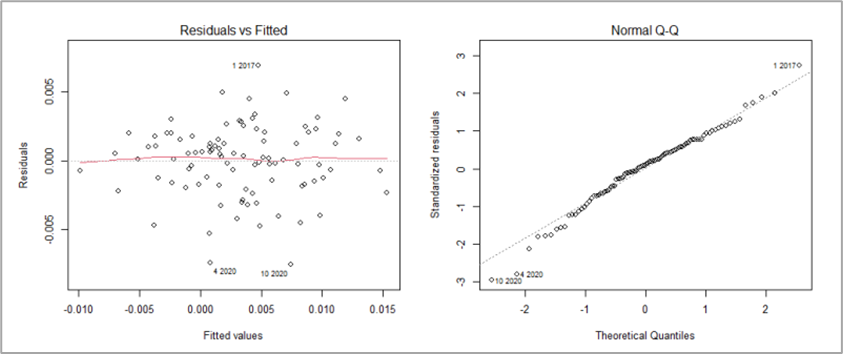
이어서 residual plot을 통해 모델의 성능을 평가하였습니다. residual-fitted plot에서 0 주변에서 관측되는, 기울기 가 0인 빨간 선을 기준으로 이상치 데이터 세 가지를 확인했으나 0을 중심으로 특정한 패턴을 가지고 있지 않음을 파악하였습니다. 또한 잔차가 0을 중심으로 크게 벗어나지 않았기 때문에, 잔차의 등분산성을 만족한다고 평가하였습니다. QQ plot에서도 잔차가 직선에서 크게 벗어나지 않음을 확인할 수 있기에 잔차의 정규성 역시 만족한다고 결론내렸습니다.
☑️ Acf plot
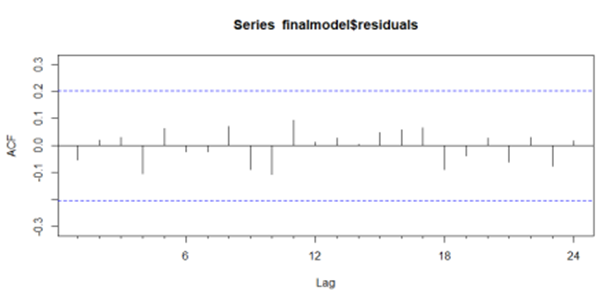
ACF 그래프에서 모든 시차에 대해 파란 구간 안에 포함되는 것을 확인하였습니다. 따라서 선정한 모델은 독립변수의 잔차의 독립성을 만족합니다.
💰 결론
분석 결과, 물가지수의 선행 값과 자본수지, 무역수지, 유가, 환율, 주택매매가가 유의미한 영향을 미쳤습니다. 또한 전쟁의 영향과 월별 더미 변수를 통한 계절조정 역시 크게 작용했습니다.
본 프로젝트를 통해, CPI와 연관된 경제 지표들을 선정하고 이와 관련된 정책을 고안하고자 합니다. 특히 주요 수 출국인 우리나라의 소비자물가지수는 외국과의 거래와 관련된 변수들의 영향을 많이 받고 있기 때문에, 외화 가 치 안정화를 통한 물가 안정화 정책이 필요하다고 생각합니다. 이와 관련된 정책으로는 지난 학기 수행한 동일 주제 프로젝트에서 아세안+3 통화스와프를 기조로 한 추가적인 외환스와핑 제도를 제안한 바 있습니다. 이에 더해, 선택된 독립변수들 중 유일하게 우리나라 국내 지표라 할 수 있는 주택매매가에 대한 정책을 마련하고자 하였습니다. 하지만 해당 변수는 경기의 흐름이나 이자율, 정책, 지역 요인 등의 다양한 원인이 변수의 증감에 큰 영향을 미쳤을 것이기에 이와 관련된 정책을 섣불리 판단하기에는 무리가 있다고 판단하여 현행 규제를 확인해 기대효과를 진단하였습니다. 결론적으로 주택매매가가 오르는 경우 소비자물가지수 역시 상승하는 관계를 보여주고 있기 때문에, 현재 진행하고 있는 규제 완화를 통해 주택 공급량을 증가시키고 최종적으로 주택매매가를 낮춰 소비자물가를 안정시키는 데에 일부 기여할 수 있기를 기대합니다.
💰 한계점 및 소감
분석 결과 유의한 변수는 우리나라 내에서 정해지는 변수보다는 외국과의 관련성에 의한 변수가 유의한 경우가 많았습니다. 프로젝트 기획 단계에서 반도체 가격 추세와 같이 우리나라 내의 변수들을 좀 더 많이 사용했다면 보다 다양한 요인을 분석할 수 있었을 것 같아 아쉽습니다. 또한 선형회귀 프로젝트를 진행할 때처럼 주로 자기상관을 줄이는 데에 집중했던 진행과정에 있어 미련이 남습니다. 시계열 데이터인 만큼, 수치적인 해석보다는 경제적 의미에 초점을 두고 진행했더라면 오히려 범용성이 넓은 모델이 나오지 않았을까 싶습니다.
그럼에도 프로젝트를 진행하면서 많은 것을 배웠습니다. 특히 직접 시계열 모델을 사용하고 적합해보면서 지난 학기 진행했던 선형회귀 프로젝트와는 변수 채택이 어떻게 다른지, 결과는 어떻게 다른지 확인할 수 있어 프로젝트 진행 과정 내내 재미있었습니다. 적합하는 과정은 역시 인내심이 필요한 일이라는 것을 다시 한번 느꼈고, 성능이 괜찮은 모델이 나온 것 같아 만족스러운 프로젝트였습니다.
💰 프리젠테이션 자료