모바일은 화면을 돌려 가로화면으로 보시는 게 읽으시기 편할 수 있습니다. 돌려서 보시는 걸 추천드릴게요!!

🩸 앞선 글에서 만든 transaction data로부터 각 column 들의 여러가지 패턴들을 구해봅시다.
🩸 코드 진행의 이해를 위해 이번 글에서 사용할 데이터프레임을 먼저 보도록 합시다.
📝 1. pre_tran : 수치형/범주형 attribute가 섞여있던 원래 데이터를 범주형 데이터로 만든 것
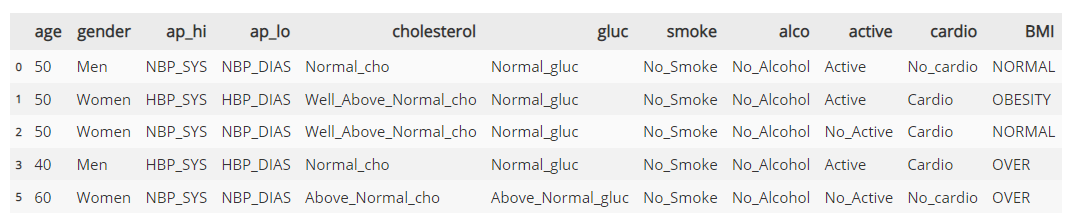
📝 2. transaction : pre_tran을 사용하여 만든 최종 트랜잭션 데이터 - Boolean 표현형
🫀 1. support / confidence / lift 구하기
🩸 패턴을 분석해서 어떤 attribute가 cardio label과 자주 등장하는지 알아보는 것이 패턴 분석의 목적입니다.
🩸 이를 위해서는 attribute를 선택하기 위한 기준이 필요한데, 각 method의 기준은 아래와 같습니다.
🩸 찾고자 하는 것은 cardio에 영향을 미치는 attribute이기에 cardio를 consequents로 하는 경우를 살펴봅니다.
▪ confidence, Lift, support 순서로 우선순위를 설정
▪ min_confidence = 0.6 & Lift > 1 & min_support = 0.01
▪ support를 낮게 설정한 이유는
confidence와 Lift를 만족할 때 antecedents의 support가 너무 작아 전체적인 support가 낮게 나오는 경우를 고려한 것입니다.
🩸 이제 본격적으로 패턴을 분석해보도록 합시다.
📌 1.1. Age / Cardio
# apriori 알고리즘, association_rules 생성
# mlxtend.frequent_patterns 모듈의 apriori, association_rules 임포트
from mlxtend.frequent_patterns import apriori, association_rules# pre_tran dataframe으로부터 원하는 attribute만을 추출
# 해당하는 attribute의 category에 대한 transaction dataframe 생성
Age_C = pre_tran[['age','cardio']]
train_data_Age_C = np.array(Age_C)
train_data_Age_C = np.array(train_data_Age_C.tolist())
te = TransactionEncoder()
te_Age_C = te.fit(train_data_Age_C).transform(train_data_Age_C)
transaction_Age_C = pd.DataFrame(te_Age_C, columns=te.columns_)
# mlxtend.frequent_patterns 모듈의 apriori, association_rules 함수
# apriori() : itemsets 간의 Support를 계산하여 dataframe으로 반환
##설정한 min_support를 만족하는 경우만 반환
# association_rules() : antecedents(선행)과 consequents(후행)의 순서를 고려
## support, confidence, lift, leverage, conviction dataframe 반환
# association_rules() 함수의 metric, min_threshold 옵션
## 설정한 metric이 min_threshold 이상인 경우만 반환
frequent_itemsets_Age_C = apriori(transaction_Age_C, min_support=0.000001,use_colnames=True)
frequent_itemsets_Age_C = frequent_itemsets_Age_C.sort_values('support',ascending = False)
rule_Age_C = association_rules(frequent_itemsets_Age_C, metric="lift", min_threshold=0)
# cardio와 영향을 미치는 attribute 간의 인과관계를 알아보기 위해
# cardio를 consequents로 하는 경우를 반환하도록 설정
# confidence가 큰 순서대로 출력
y = rule_Age_C['consequents'].apply(lambda rule_Age_C: "Cardio" in str(rule_Age_C))
y = y[y==True].index
rule_Age_C_cardio = rule_Age_C.loc[y].sort_values('confidence', ascending = False)
rule_Age_C_cardio
만들어진 패턴 데이터프레임은 아래와 같습니다. 이를 보면, Age attribute는 설정한 기준인 min_confidence = 0.6 과 Lift > 1, min_support = 0.01 를 만족하는 경우가 있기 때문에 연관성이 있다고 볼 수 있습니다.

사실 앞으로 10개가 넘는 attribute에 대해서 이 과정을 거칠텐데, 이렇게 일일이 표를 찾아 필터링을 하기는 많이 번거롭습니다. 이에 시각화를 통해 한번에 비교해보는 것도 좋을 거라는 생각이 들었습니다.
fig = go.Figure()
fig.add_trace(
go.Scatter(
x = ['60','50','40','30'], y = rule_Age_C_cardio['support'],
name = 'Support',
mode = 'markers+text', marker_size = 20,
text = rule_Age_C_cardio['support'].round(3),
textposition = 'middle right',
textfont_size = 15)) # Support를 scatter하는 부분
fig.add_trace(
go.Scatter(
x = ['60','50','40','30'], y = rule_Age_C_cardio['confidence'],
name = 'Confidence',
mode = 'markers+text', marker_size = 20,
text = rule_Age_C_cardio['confidence'].round(3),
textposition = 'middle right',
textfont_size = 15)) # Confidence를 scatter하는 부분
fig.add_trace(
go.Scatter(
x = ['60','50','40','30'], y = rule_Age_C_cardio['lift'],
name = 'Lift',
mode = 'markers+text', marker_size = 20,
text = rule_Age_C_cardio['lift'].round(3),
textposition = 'middle right',
textfont_size = 15)) # Lift를 scatter하는 부분
# Lift 판단 기준(Lift > 1)을 나타내기 위한 수평선 plot
fig.add_hline(y=1, line_dash="dot",
line_color = "#1dd1ad",
annotation_text=" Lift > 1",
annotation_position="bottom left",
annotation_font_size=17,
annotation_font_color="gray"
)
# support 판단 기준(support > 0.01)을 나타내기 위한 수평선 plot
fig.add_hline(y=0.01, line_dash="dot",
line_color = "#8c8cf5",
annotation_text=" support > 0.01",
annotation_position="bottom left",
annotation_font_size=17,
annotation_font_color="gray"
)
# confidence 판단 기준(confidence > 0.6)을 나타내기 위한 수평선 plot
fig.add_hline(y=0.6, line_dash="dot",
line_color = "#ff0000",
annotation_text=" confidence > 0.6",
annotation_position="bottom left",
annotation_font_size=17,
annotation_font_color="gray"
)
fig.update_layout(
{
'title' : {'text':'Age-Cardio 별 Support, Confidence, Lift 값',
'font':{'size' : 25}},
'xaxis' : {'title':{'text' : 'Age', 'font':{'size' : 20}},
'showticklabels':True,
'tickfont' : {'size' : 15}},
'yaxis' : {'title':{'text' : 'Support / Confidence / Lift',
'font':{'size' : 20}}, 'showticklabels':True,
'tickfont' : {'size' : 15}},
'template' : 'plotly_dark'
})
fig.show()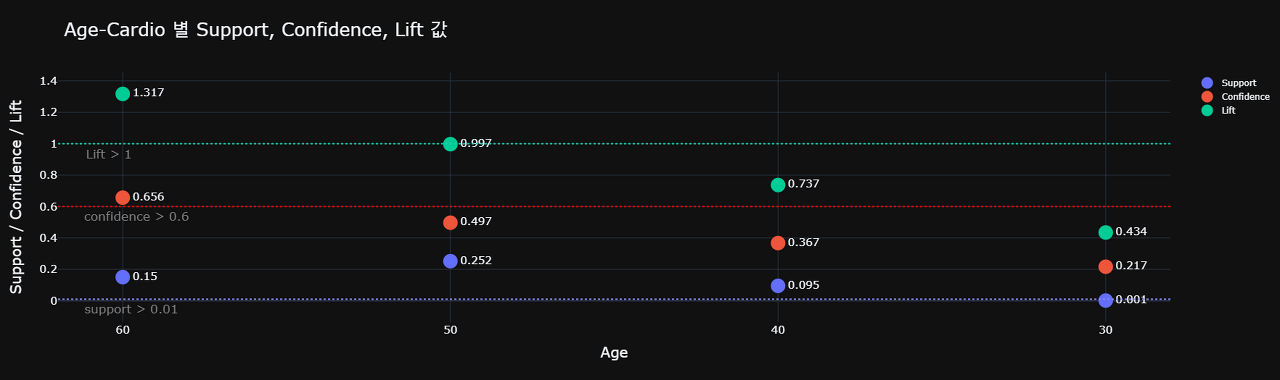
위의 도표에서 볼 수 있듯이 각 패턴 메소드의 기준값에 수평선을 그어 한눈에 들어오기 편하게 시각화했습니다. 이제 다른 attribute를 분석해보도록 하겠습니다!!
📌 1.2 Gender / Cardio
# 전자와 동일
Gender_C = pre_tran[['gender','cardio']]
train_data_Gender_C = np.array(Gender_C)
train_data_Gender_C = np.array(train_data_Gender_C.tolist())
te = TransactionEncoder()
te_Gender_C = te.fit(train_data_Gender_C).transform(train_data_Gender_C)
transaction_Gender_C = pd.DataFrame(te_Gender_C, columns=te.columns_)
frequent_itemsets_Gender_C = apriori(transaction_Gender_C, min_support=0.0000001,use_colnames=True)
frequent_itemsets_Gender_C = frequent_itemsets_Gender_C.sort_values('support',ascending = False)
rule_Gender_C = association_rules(frequent_itemsets_Gender_C, metric="lift", min_threshold=0)
y = rule_Gender_C['consequents'].apply(lambda rule_Gender_C: "Cardio" in str(rule_Gender_C))
y = y[y==True].index
rule_Gender_C_cardio = rule_Gender_C.loc[y].sort_values('confidence', ascending = False)
#시각화
fig = go.Figure()
fig.add_trace(
go.Scatter(
x = ['Women','Men'], y = rule_Gender_C_cardio['support'],
name = 'Support',
mode = 'markers+text', marker_size = 20,
text = rule_Gender_C_cardio['support'].round(3),
textposition = 'middle right',
textfont_size = 15))
fig.add_trace(
go.Scatter(
x = ['Women','Men'], y = rule_Gender_C_cardio['confidence'],
name = 'Confidence',
mode = 'markers+text', marker_size = 20,
text = rule_Gender_C_cardio['confidence'].round(3),
textposition = 'middle right',
textfont_size = 15))
fig.add_trace(
go.Scatter(
x = ['Women','Men'], y = rule_Gender_C_cardio['lift'],
name = 'Lift',
mode = 'markers+text', marker_size = 20,
text = rule_Gender_C_cardio['lift'].round(3),
textposition = 'middle right',
textfont_size = 15))
fig.add_hline(y=1, line_dash="dot",
line_color = "#1dd1ad",
annotation_text=" Lift > 1",
annotation_position="bottom left",
annotation_font_size=17,
annotation_font_color="gray"
)
fig.add_hline(y=0.01, line_dash="dot",
line_color = "#8c8cf5",
annotation_text=" support > 0.01",
annotation_position="bottom left",
annotation_font_size=17,
annotation_font_color="gray"
)
fig.add_hline(y=0.6, line_dash="dot",
line_color = "#ff0000",
annotation_text=" confidence > 0.6",
annotation_position="bottom left",
annotation_font_size=17,
annotation_font_color="gray"
)
fig.update_layout(
{
'title' : {'text':'Gender-Cardio 별 Support, Confidence, Lift 값',
'font':{'size' : 25}},
'xaxis' : {'title':{'text' : 'Gender', 'font':{'size' : 20}},
'showticklabels':True,
'tickfont' : {'size' : 15}},
'yaxis' : {'title':{'text' : 'Support / Confidence / Lift', 'font':{'size' : 20}},
'showticklabels':True,
'tickfont' : {'size' : 15}},
'template' : 'plotly_dark'
})
fig.show()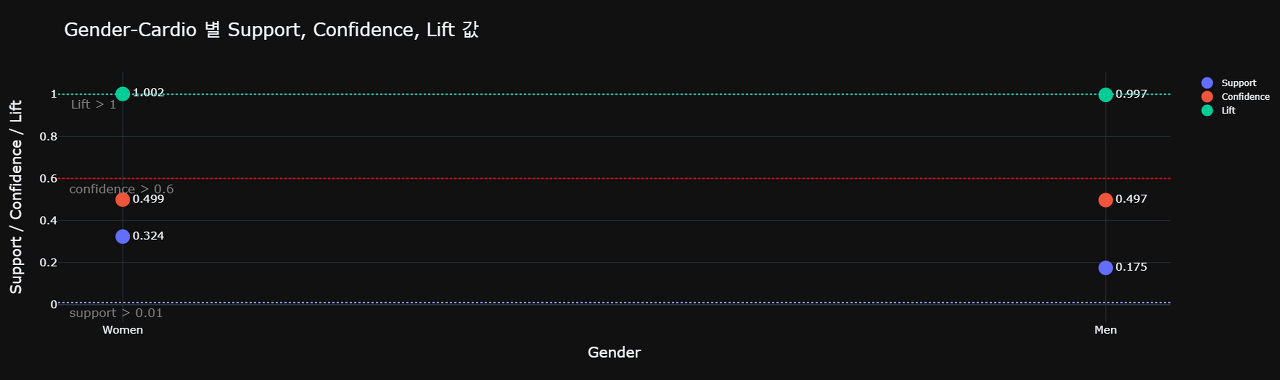
설정한 기준인 min_confidence = 0.6 / Lift > 1 / min_support = 0.01 를 만족하는 경우가 없기에 연관성이 있다고 보기 힘들 것 같습니다.
📌 1.3. BMI / Cardio
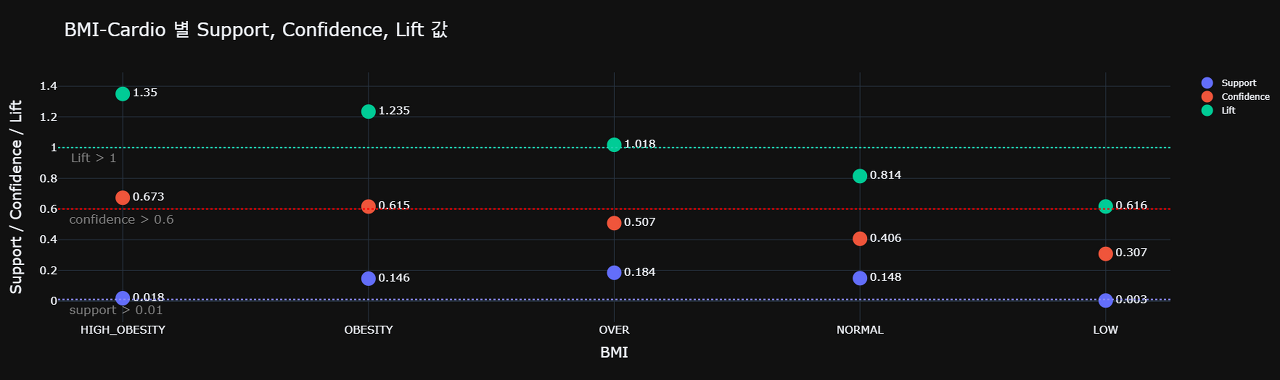
설정한 기준인 min_confidence = 0.6 / Lift > 1 / min_support = 0.01 를 만족하는 경우가 있기 때문에 연관성이 있다고 볼 수 있습니다.
🚩 나머지 모든 attribute에 대해서도 support, confidence, lift를 구한 결과는 아래와 같습니다.
📌 1.4. Support / Confidence / Lift 결과
🩸 min_confidence = 0.6 & Lift > 1 & min_support = 0.01 를 만족하는 attribute 추출
▪ age, ap_hi, ap_lo, cholesterol, gluc, BMI
▪ 앞서 수행한 correlation 결과에 gluc attribute가 포함된 집합입니다.
🩸 이번 글에서는 패턴을 분석하기 위해 위의 세가지 방법을 사용하였습니다. 하지만 한 가지 생각할 점이 있는데, 우리가 사용한 트랜잭션 데이터가 Null value에 영향을 받을 수 있다는 점입니다. 이 경우 이론적으로 Null-invariant measure를 사용하는 것으로 알고 있기 때문에, 저희는 Kulczynski 값과 Imbalanced Ratio 값을 사용해서 패턴을 분석할 것입니다. 이 과정은 다음글에서 다루도록 하겠습니다.😊😊.
🩸 거듭 말하지만, 이 프로젝트는 수업에서 배운 내용을 직접 사용해서 데이터로부터 인사이트를 뽑아내기 위한 프로젝트입니다!! 미숙하지만, 흥미있게 읽어주셨으면 합니다~~
'🐍 파이썬 데이터 분석 프로젝트 > 🫀 심혈관질환 데이터 분석' 카테고리의 다른 글
| 🫀 심혈관질환 데이터 분석 09. Kulczynski (0) | 2023.02.01 |
|---|---|
| 🫀 심혈관질환 데이터 분석 08. 카이제곱검정 (0) | 2023.02.01 |
| 🫀 심혈관질환 데이터 분석 06. 패턴분석 데이터 전처리 (0) | 2023.01.31 |
| 🫀 심혈관질환 데이터 분석 05. 상관관계 분석 (0) | 2023.01.31 |
| 🫀 심혈관질환 데이터 분석 04. attribute 노이즈 확인 (0) | 2023.01.29 |