모바일은 화면을 돌려 가로화면으로 보시는 게 읽으시기 편할 수 있습니다. 돌려서 보시는 걸 추천드릴게요!!

🎁 코호트 차트 및 LOD 식 사용하기 (📆 2023.03.20 ~ 2023.03.23)
🎁 1. 코호트 차트
(1) superstore_sample 데이터셋
먼저, 올려주신 영상을 보고 그대로 따라서 차트를 구현하였습니다.
위 차트를 분석해보면, 2019년 4분기에 첫 구매가 이뤄진 고객의 경우 같은 분기에 두번째 주문을 할 정도로 재주문 성호도가 높다고 할 수 있을 것 같습니다. 또한, 2019년 3분기에 첫 구매를 한 고객은 다음 분기와 그 다음 분기에 두번째 주문을 하는 경우가 많았습니다. 특히 두분기 후에 구매가 이루어진 경우 해를 넘어서 재구매를 한 고객이기 때문에 더욱 유의미한 재구매라고도 볼 수 있을 것 같습니다. 다만, 최근 들어서 전반적인 구매량과 재구매량이 상당히 줄어들었습니다. 이를 해결할 방안을 모색할 필요가 있어 보입니다.
Q1. 태블로를 하면서 항상 생기는 의문점인데, 위 차트에서의 빈 부분처럼 아무런 값이 없는 경우를 0으로 채우는 방법이 있는지 궁금합니다!! 계산된 필드를 만든 결과 해당 경우(예를 들어 2020년 2분기에 주문해서 0분기 후에 다시 구매한 경우)의 Customer ID 를 카운트한 결과가 0으로 집계되기 때문에 0이라는 값이 채워질 줄 알았는데, 그렇지 않았습니다. 해결할 수 있는 방법이 있을까요??
(2) B2B Online shopping 데이터셋
다른 데이터로 코호트 차트를 그려보고자 캐글에서 데이터를 가져왔습니다.
https://www.kaggle.com/datasets/anamsken/b2b-online-shopping-platform-dataset
B2B online shopping platform dataset
Analyze this B2B shopping record with over 11,000 records
www.kaggle.com
23개의 다양한 column을 가지고 있는 데이터에서, 각 주문 월에 따른 주 단위 배송 기간을 알아보고자 했습니다. 따라서 [고객 ID, 주문 날짜, 도착 날짜] 에 해당하는 column을 가져와 코호트 차트를 구현하였습니다. 결과는 아래와 같습니다.
분석 결과, 대부분의 배송은 3주 내지 4주 안에 모두 완료되는 것을 확인할 수 있었습니다. 그 외 배송기간이 굉장히 오래 걸린 물품들은 해당 물품의 종류와 주문자가 단체인지, 개인인지에 따른 영향을 받을 것이기에 이에 대한 분석 역시 필요해 보입니다. 다만 해당 과제에서는 코호트 차트 구현이 목적이기 때문에, 해당 분석에 대해서는 미래의 저에게 맡겨둘 생각입니다. 또한 시간이 지날수록 주문자의 수가 꾸준히 증가하고 있기 때문에, 본 온라인 쇼핑몰은 계속해서 성장중이라고 말 할 수 있을 것 같습니다!!
Q2. 코호트 차트 구현을 위해 여러 가지 데이터를 살펴봤는데, 생각보다 특정 기간에 특정 경험을 공유한 집단 간의 행동 패턴을 비교하여 분석한다는 코호트 분석의 정의를 만족할 만한 데이터를 찾기는 어려웠던 것 같습니다. 코호트 분석을 주로 사용하는 분야나 산업군이 있다면 어떤 분야가 있을지, 그리고 어떠한 경우에 주로 사용하는지 알려주시면 감사하겠습니다!!
🎁 2. 세명고 학업성취도 데이터 분석
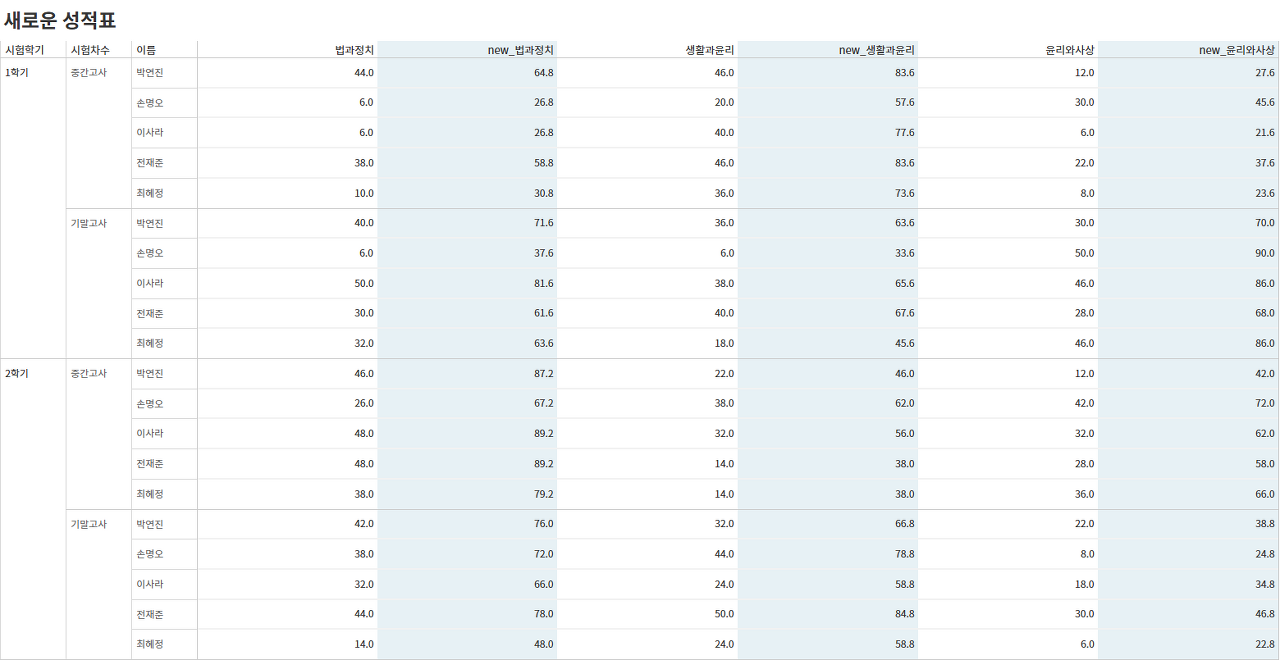
(1) 새로운 성적표 만들기
학기 별 전체 학생들의 평균과 해당 학생의 점수를 합하여 새로운 성적을 산출하기 위해 아래의 계산식을 사용하였으며, 나머지 두 과목에 대해서도 같은 연산을 수행하여 테이블을 구성하였습니다.
|
|
|
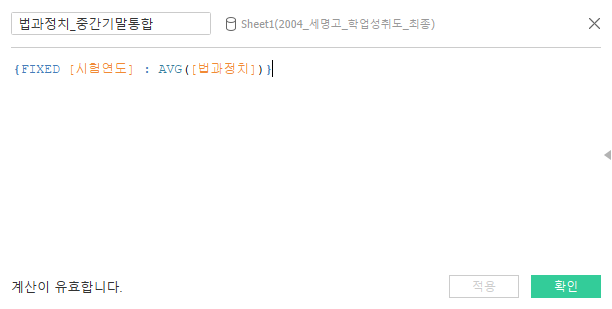
(2) 뷰와 다른 참조선 만들기
뷰에는 기말고사에 대한 정보가 없는 상황에서, 참조선에는 기말고사의 성적이 반영된 평균을 나타내는 것이 문제였습니다. [시험연도 - 시험학기 - 시험차수 - 이름] 순으로 데이터가 세분화되고 있는 상황에서, 문제에서 요구하는 것은 가장 넓은 범위 하에서 평균을 구하는 것이라고 생각했습니다. 이를 해결하기 위해 아래의 계산식을 사용했습니다. 법과정치 이외의 다른 과목들에 대해서도 같은 연산을 수행하였습니다. 이후, 각 계산식을 매개변수로 만들어 참조선 사용 시 사용하고자 했습니다.
이후 각 과목의 성적을 열 선반에 올려주고, 참조선을 추가할 때 옵션으로 앞서 정의한 매개변수를 지정해 문제에서 요구한 차트를 만들 수 있었습니다. 결과는 아래와 같습니다. 각 학생들의 성적임을 나타내기 위해서, 이름에 대해 색상을 지정해주었습니다.
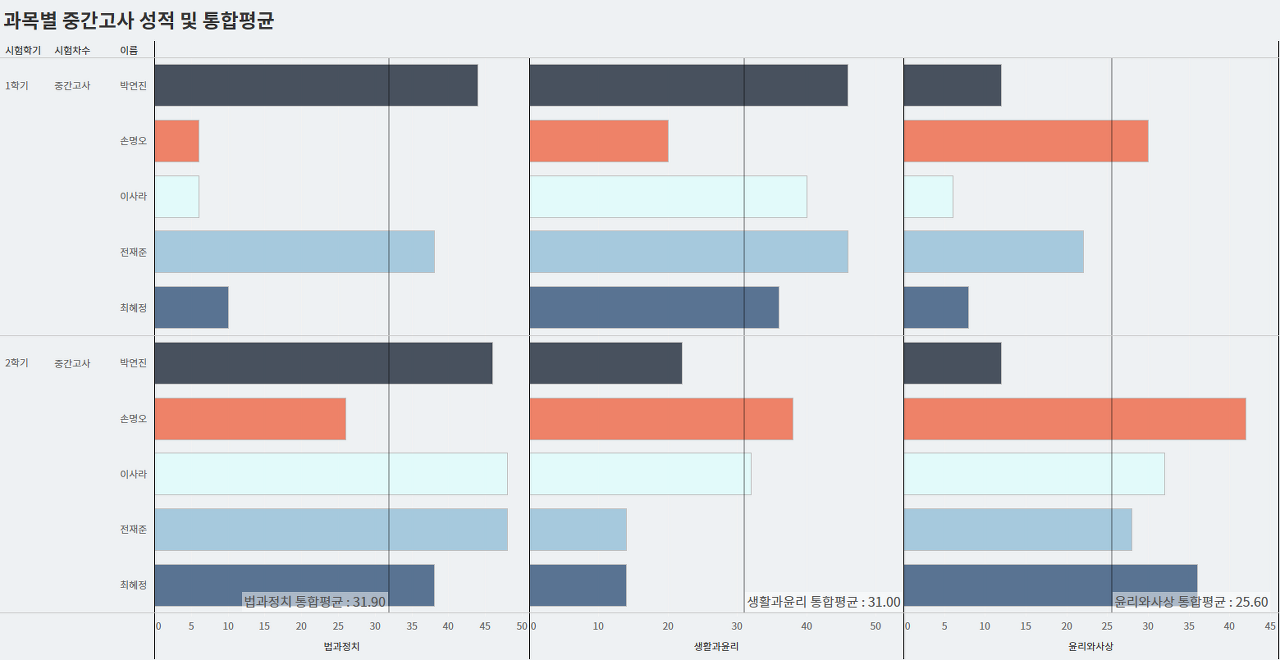
세명고 2번 문제를 풀 때 데이터가 어떠한 방식으로 세분화되는지 생각하지 않고 무작정 LOD 식만 만들어보느라 시간이 많이 걸렸습니다. 구글에서 괜히 어려운 식을 보고 구현하느라 태블로가 어렵다는 생각이 들었던 것 같은데, 밑져야 본전이라는 식으로 만들어본 필드가 제대로 된 결과를 만들어내서 당황스러웠던 것 같습니다. 이번 과제를 통해 차트를 구현할 세분화 수준을 정하는 것이 중요하다는 것도 알게 되었고, 원하는 색상의 팔레트를 정의하는 방법도 알게 되어 앞으로 좀 더 가독성있는 차트를 만들 수 있을 것 같습니다!!
'🔥 태블로 분석 프로젝트 > 🎁 슈퍼스토어 코호트 차트 분석' 카테고리의 다른 글
| 🎁 4주차 분석 피드백 (0) | 2023.04.02 |
|---|