모바일은 화면을 돌려 가로화면으로 보시는 게 읽으시기 편할 수 있습니다. 돌려서 보시는 걸 추천드릴게요!!

🩸 2022-1 학기에 진행한 데이터 마이닝 프로젝트를 요약할 생각입니다. 진행한 프로젝트는 Cardio-Vascular Disease Prediction 으로, 심혈관 질환을 예측하는 모델을 만드는 것이 프로젝트의 목적이었습니다.
🩸 이 프로젝트를 위해 캐글에서 해당 데이터를 가져왔으며, 링크는 바로 아래에 첨부해 두었습니다.
Cardiovascular Disease dataset
The dataset consists of 70 000 records of patients data, 11 features + target.
www.kaggle.com
🩸 이번 포스팅에서는 사용할 데이터를 설명할 것입니다.
🫀 Attributes
🩸 데이터를 불러오고 프로젝트 진행을 위해 아래와 같은 라이브러리들을 미리 임포트했습니다. 데이터 전처리 과정에는 아래의 모듈들만 있으면 되고, 프로젝트를 진행하면서 추가적인 라이브러리들을 임포트할 예정입니다.
# 데이터 임포트, 전처리를 위한 pandas, numpy library 임포트
import pandas as pd
import numpy as np
# 시각화를 위한 plotly library 임포트
import plotly.graph_objects as go
import plotly.offline as pyo
pyo.init_notebook_mode()
🩸 먼저 데이터를 불러오겠습니다.
cardio = pd.read_csv('C:\\Users\mingu\Desktop\\cardio_train.csv', sep=';')
cardio
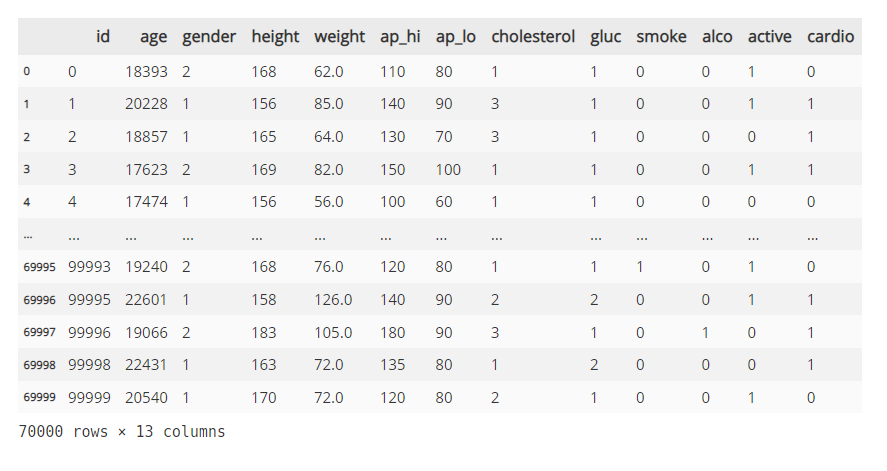
🩸 차후 진행을 위해 이름을 cardio 라고 붙였고, 일반적인 CSV 파일은 콤마(,) 로 구분이 되기에 pd.read_csv() 만을 사용하여 불러올 수 있지만 저희 팀이 사용한 데이터는 세미콜론(;) 으로 구분되어 있었기 때문에 sep=';' 옵션 을 넣어 데이터를 불러왔습니다.
🩸 각 attribute가 무엇을 의미하는지 살펴보겠습니다.
▪ 나이
▪ 성별(1-women, 2-men)
▪ 키(cm)
▪ 몸무게(kg)
▪ ap_hi(systolic blood pressure, 수축혈압)
▪ ap_lo(diastolic blood pressure, 이완혈압)
▪ cholesterol(1-normal, 2-above normal, 3-well above normal)
▪ gluc(혈당)(1-normal, 2-above normal, 3-well above normal)
▪ smoke(0-비흡연, 1-흡연)
▪ alco(0-음주X, 1-음주O)
▪ active(운동여부)(0-X, 1-O)
▪ Cardio(target)(0-X, 1-O)
🩸 부가적인 전처리가 필요하겠지만, 결론적으로는 상위 11개의 attribute를 가지고 마지막 Cardio attribute 를 예측하는 것이 최종적인 프로젝트의 목표입니다.
🩸 전처리에 대해서는 다음 포스팅에서 다룰 예정입니다.
'🐍 파이썬 데이터 분석 프로젝트 > 🫀 심혈관질환 데이터 분석' 카테고리의 다른 글
| 🫀 심혈관질환 데이터 분석 06. 패턴분석 데이터 전처리 (0) | 2023.01.31 |
|---|---|
| 🫀 심혈관질환 데이터 분석 05. 상관관계 분석 (0) | 2023.01.31 |
| 🫀 심혈관질환 데이터 분석 04. attribute 노이즈 확인 (0) | 2023.01.29 |
| 🫀 심혈관질환 데이터 분석 03. 데이터 전처리 (0) | 2023.01.29 |
| 🫀 심혈관질환 데이터 분석 01. readme (0) | 2023.01.29 |