모바일은 화면을 돌려 가로화면으로 보시는 게 읽으시기 편할 수 있습니다. 돌려서 보시는 걸 추천드릴게요!!

🏆 LSTM을 사용한 EEG 데이터 딥러닝 프로젝트
EEG란 두피에 전극을 부착해 뇌의 미세한 전기활동을 증폭해 파동을 기록하는 검사입니다. 흔히 말하는 뇌파가 이 검사로부터 나오는 결과를 의미합니다. 뇌파검사는 현재 질병진단, 의학교육, 치료목적 등으로 연구 중입니다. 특히 ADHD, 자폐증, 우울증, 뇌종양 등 여러가지 정신질환과 중추신경계질환 진단에 도움을 줄 수 있습니다. 이러한 배경을 바탕으로 EEG 결과를 분석해 간단한 검사만으로 질환을 예측하는 모델을 만듦으로써 많은 사람들이 가질 수 있는 위험성을 사전에 방지하고자 합니다.
🏆 주제 선정 배경
📌 간질(epilepsy, 뇌전증)은 두통 다음으로 가장 흔한 만성질환으로 꼽힙니다. 이에 더해 전 세계적으로 유병률이 0.7~1%로 비슷하기 때문에 어느 인종에 한해서 나타나는 증상이 아닌 흔한 질환이라고 말할 수 있습니다. 간질을 일으키는 원인은 다양하지만, 그들의 공통점은 뇌의 신경세포에 영향을 주거나 신경세포의 정상적인 기능을 방해하는 일을 야기한다는 것입니다. 또한 뇌의 어느 부위에 손상이 가느냐 혹은 뇌의 어느 부분에서 전기 방전이 일어나느냐에 따라 간질 발작의 반응이 다양하기 때문에 다른 질환에 비해 뇌의 이상유무를 잘 파악해야 할 필요가 있습니다. 다행히 대부분의 증상은 약물의 처방으로 조치가 되지만, 해당 약물의 복용을 그만두는 경우 발작이 다시 발생할 수 있습니다. 아래의 자료를 보면 더욱 잘 이해할 수 있을 것입니다.
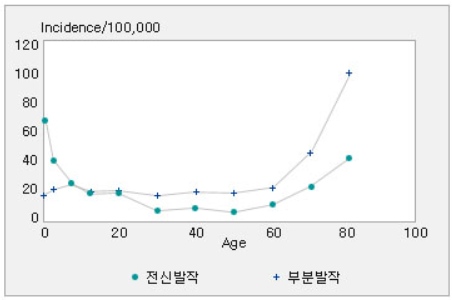
📌 위의 도표에서 확인할 수 있듯이 10대 이전 그리고 50-60대 연령에서 간질 발작을 일으키는 경우가 많음을 알 수 있습니다. 어린 나이에는 신체적 발달이 완전히 진행되지 않은 상태이기에 사소한 자극에도 뇌의 전기적 반응으로 인한 간질이 잘 일어날 수 있습니다. 이후 40대가 넘어가면서 호르몬적 변화가 일어나고, 복용하는 다른 목적의 약의 처방으로 인한 side effect로 간질을 겪을 수 있습니다.
📌 이에 본 프로젝트를 통해 EEG 신호를 LSTM 모델에 적용해 질환을 예측하고 큰 위험을 사전에 예방하는 것에 일조하고자 합니다.
🏆 데이터
💡 본 프로젝트에 사용한 데이터는 아래의 링크에서 추출하였습니다.
☑️ EEG 데이터
Epileptic Seizure Recognition
epileptic seizure detection
www.kaggle.com
☑️ 해당 데이터는 23.5초 동안 500명의 피실험자로부터 관측된 뇌파를 기록한 데이터입니다. 그렇게 얻어진 500 x 4097개의 데이터를 23개로 분할하고 셔플링하여 1초당 178개의 측정값을 보유하도록 조정했으며, 500명의 23개 셔플값이기에 총 11500 개의 행을 가지고 있습니다. 얻어진 데이터를 바탕으로 셔플링하여 한 사람이 가지는 특정성을 제거하였습니다. 이에 본 프로젝트가 취지로 가지는 무작위적인 대상 적용에 가장 적절한 데이터라 판단하였습니다.
☑️ 원본 데이터는 label을 1,2,3,4,5 로 구분하여 1의 경우 간질발작을 보유한 사람의 뇌파를, 2의 경우 뇌종양이 있는 부분에서 나타난 뇌파를 측정하였으며, 3,4,5 의 경우에는 정상인의 뇌파 중 다양한 신체 반응에 의해 달라지는 뇌파를 측정하였습니다. 저희 팀은 클래스가 너무 다양하면 local한 각각의 개체에 모델이 최적화될 것을 우려하였습니다. 따라서 3,4,5 label을 하나의 정상 범주로 묶어 모델을 학습시킴으로써 간질을 예측할 수 있도록 하는 것에 최대한 초점을 맞추었습니다.
🏆 LSTM 모델 선정 이유
💡 이러한 생체신호계측기기를 통해 얻어진 데이터는 시계열 데이터인 경우가 많습니다. 이에 자연어 처리 혹은 텍스트 처리를 위해 주로 사용하는 RNN 모델을 사용하기로 하였고, 뇌파 데이터의 특성 상 노이즈가 많을 것으로 예측하였기 때문에 이를 잘 처리할 것이라 생각되는 LSTM 모델을 사용하였습니다.
🏆 분석결과
☑️ EEG 신호가 sequential data이기 때문에, 전반적으로 높은 예측을 보여줄 것이라 생각한 RNN모델을 사용하였습니다. 수업시간에 다룬 3가지 방법(vanila RNN, GRU, LSTM) 중에서 LSTM 이 가장 좋은 퍼포먼스를 보여주었기 때문에 LSTM을 선택했습니다. Accuracy Curve는 아래와 같이 높은 예측 점수를 보여주었습니다.

☑️ 만들고자 하는 모델은 사용자의 EEG sequence를 넣었을때 그 사람이 어떤 상태(간질발작-0, 종양-1, 건강-2)에 놓여있는지를 파악하는 모델입니다. 측정을 위한 전극의 위치나 개수를 고려하여 이미 한번 셔플한 데이터였지만, 보다 랜덤한 표본을 통해 모델을 학습시키기 위해서 임의의 랜덤한 부분에서 120개의 신호를 가져올 수 있도록 data_iter와 모델을 설계하였습니다. 이는 inference부분에도 동일하게 구현하였습니다.
☑️ 학습결과 전반적으로 높은 accuracy를 보여주었기에 vallidation data를 input으로 입력했을 때 결과 역시 대부분의 경우에도 제대로 예측하였습니다. 그럼에도 제대로 파악하지 못하는 몇가지 경우(test_x_st[1003], label = 2)를 분석하기 위해 신호의 파형을 출력해 보았습니다. test_x_st[1003]의 경우에는 원래 label이 2지만, 실제 inference를 돌려보면 1로 예측하는 경우가 존재했습니다. label이 2인 다른 샘플을 예측할 때에는 제대로 예측을 하는 것으로 보아, 이는 아래의 그림에서 보듯이 label이 1인 [996]과 유사한 패턴이 [1003]의 파형에 존재하기 때문으로 사료됩니다. 랜덤한 범위에서 L개의 데이터를 추출하도록 설계해 두었기 때문에, 그 유사한 부분을 함께 가져오면서 잘못된 예측을 할 가능성이 생긴 것 같습니다. 어쩌면 label 2를 결정하는 부분이 파형에 존재하는 자잘한 변화들 때문이라 생각했습니다만, [1003]의 파형은 [2496]과는 다르게 그 자잘함이 눈에 띄지는 않습니다. 하지만, inference를 다시 진행하여 새로운 L의 범위를 랜덤하게 받아오면 제대로 예측하는 것을 확인할 수 있었습니다.

☑️ 위에서의 예 뿐만 아니라 서로 다른 label을 가지고 있으나 유사한 부분이 신호에 존재하는 경우에는 예측이 틀리는 경우가 존재하였습니다. 이는 아무래도 랜덤하게 추출하는 과정에서 신호의 이어짐이 끊긴 이유도 있을 테지만, 기장 큰 이유는 사람이 신호의 파형만을 보고 EEG 신호의 노이즈를 판별하여 분석해내기에는 어려움이 따르기 때문이라고 생각합니다. 반면 같은 이유로 inference를 할때 랜덤한 구간 L을 설정해주기 때문에 잘못 예측한 경우 역시 inference를 다시 진행해보면 대다수가 원래의 label과 일치하는 것을 확인할 수 있습니다.
☑️ 무의식적인 뒤척거림이나 눈 움직임에 의해 신호에 큰 변화가 일어나는 EEG 신호를 사용했기 때문에 이를 어느정도 보정해주기 위한 적절한 표준화 방법이 필요했습니다. 따라서 신호의 noise를 제거해주기 위해 moving average와 MinMaxScaler, StandardScaler를 각각 적용해보았는데 StandardScaler의 경우에 가장 좋은 결과를 나타냈기 때문에 이 method를 선택해서 학습을 진행했습니다.
☑️ 모델의 일반성을 확인해보기 위해서 다른 EEG data(945 rows, 1149 columns)를 적용해서 classification을 진행하였으나, 이 데이터에 대해서는 좋은 결과를 얻지 못했습니다. 우선적으로 해당 데이터의 7개의 label들에 대한 분포가 고르지 않았습니다. 또한 본 프로젝트에 사용한 데이터(11500 rows, 179 columns)에 비해 column의 수는 많지만, 그 수많은 EEG 신호에 대한 노이즈를 잡아 결과를 얻기에는 object의 수가 너무 적었기 때문이라고 생각합니다.
☑️ 결론적으로 EEG 신호처럼 노이즈가 많은 데이터를 분석하기 위해서는 이를 잘 설명해줄 수 있을 만한 충분한 수의 데이터와 적절한 scaler 방법이 필요하다고 생각합니다. 또한 앞서 말했듯 사람이 이러한 노이즈를 잡아내고 패턴을 분석해서 그에 해당하는 인사이트를 도출하기는 너무 어렵기 때문에 EEG 신호와 같은 의학적 분야에 인공지능이 꼭 필요할 것이라고 결론을 내렸습니다.
🏆 질문에 대한 답변
❓ class간 비율이 1:1:3으로 normal이 상대적으로 많은데 이로 인한 문제가 없을까요?
❓ class별로 accuracy를 각각 분석하여 주세요.
☑️ 위 질문들에 대한 답을 위해 classification report와 confusion matrix를 출력했습니다. 그 결과는 아래와 같았습니다.

☑️ 사실 첫번째 질문과 두번째 질문에 대한 답을 이 두개의 결과로부터 모두 알아볼 수 있을 것 같습니다. 에포크를 많이 돌려서 실험한 결과 accuracy는 계속 꾸준히, 그리고 굉장히 높은 수치까지 성장한 것을 확인했지만, 아래의 report에서 볼 수 있듯이 전체적인 accuracy는 생각보다 낮게 측정되었습니다. normal이 상대적으로 많이 데이터였기 때문에 데이터가 어느 정도 불균형하다는 것을 염두에 두고, accuracy보다는 f1-score에 좀 더 비중을 두고 분석하는 것이 좋을 수 있다고 생각하였습니다. 저희 팀이 우선적으로 찾아내고 싶었던 target인 Epileptic_Seizures (label=0)에 대해서는 그 score가 0.97로 굉장히 높은 것을 확인할 수 있었고, 이에 대해서는 좋은 성능을 보이는 모델이라 할 수 있을 듯 합니다. 또한 confusion matrix 에도 나타나 있듯이, 총 500개의 label 0 에 대해서 483개의 좋은 예측을 한 모델을 만들 수 있었습니다. 하지만 상대적으로 Tumor에 대한 f1-score 는 상당히 낮은 것을 확인하였습니다. 이는 아무래도 전체적인 신호의 파형이 tumor와 normal의 경우가 비슷한 부분들이 존재하기 때문에 tumor를 정확히 파악하기에는 tumor label에 대한 비율이 살짝 부족하지 않았을까 싶습니다. 결론적으로 상대적인 비율이 저희가 주 목적으로 한 Epileptic_Seizures를 알아내는 데에는 지장이 없었지만, 다른 label, 특히 Tumor를 파악하는 데에는 영향을 미쳤다고 생각합니다.
☑️ 클래스 별 accuracy는 아래와 같습니다.
| class | accuracy |
| Epileptic_Seizures (0) | 0.966 |
| Tumor (1) | 0.652 |
| Normal (2) | 0.871 |
🏆 배운 점
☑️ 데이터를 선정하고, 전처리하기까지의 어려움은 크게 없었던 것 같습니다. 하지만 이 데이터를 우리가 원하는 형태로 바꿔주고, 랜덤하게 모델에 입력을 넣어주는 코드를 구현하는 과정과 모델과의 shape를 맞추는 데 시간이 굉장히 많이 걸렸습니다. 노력 끝에 모델의 shape를 맞춰서 학습을 시작하는 것까지는 성공을 했지만, 이어진 학습 단계에서 accuracy가 local optimum 에 빠지는 상황이 발생했기 때문에 바꿀 수 있는 건 모두 바꿔봤습니다. learning rate, epoch, optimization, loss function 그리고 각종 사이즈까지 모두 바꿔봤지만 도저히 상황이 나아지지 않았고, 밑져야 본전이라는 마음가짐으로 단순히 LSTM 함수의 num_layer를 바꾸었더니 좋은 결과를 만들 수 있었습니다. 인터넷을 찾아보며 사서 고생을 정말 많이 한 것 같은데, 오히려 간단한 매개변수를 하나 바꿔줌으로써 완전히 상반된 결과를 만들 수 있다는 것이 신기한 한편 허무하기도 했습니다.
☑️ 하지만 이런 과정을 통해 수업시간에 배운 optimize algorithm 외에도 수많은 종류가 있다는 것도 알 수 있었고, 그 중에 하나인 Adam을 선택해서 더 나은 accuracy를 얻었습니다. 또한 수업시간에 수업을 들으면서도 이렇게 학습한 모델을 실제로 어떻게 사용하는지는 항상 궁금했는데, Inference 과정을 구현해보면서 그 방법을 배운 것 같아 재미있었습니다. 수업시간에 배우는 이론도, 그리고 실습코드를 사용해서 과제를 하는 것 역시 중요하지만 그래도 제일 기억에 남는 것은 역시 직접 시간을 들여서 찾아보고, 결론을 도출하기까지의 과정인 것 같습니다. 결과적으로 저희 팀은 바이오메디컬인공지능 프로젝트를 통해 직접 데이터를 불러오고 모델에 적용하면서 그 shape 와 각종 하이퍼파라미터들을 맞추는 인공지능의 핵심을 배웠고, 그보다 중요한 하나의 인공지능을 구현해보았다는 값진 경험을 얻었습니다.
🏆 수행 역할
💡 본 프로젝트는 인공지능 과목을 수강함과 동시에 진행된 프로젝트입니다. 따라서 주제 선정 후 프로젝트 제출 만료일까지의 시간이 물리적으로 촉박하였습니다. 이에 저희 조는 주제 선정과 데이터 수집에 특히 공을 들였으며, LSTM 모델 구현을 위해서 각각의 조원이 각 파라미터를 바꾸어 가며 제일 좋은 퍼포먼스를 얻기 위해 노력하였습니다. 또한 저는 데이터마이닝 과목 수강을 통해 전반적인 데이터 처리와 통계 분석 방법을 경험해보았기 때문에, 결과 분석을 맡아 프로젝트의 결론 부분을 책임졌습니다.
💡제가 프로젝트에서 수행한 주요 역할을 정리하면 아래와 같습니다.
📌 프로젝트 주제 선정
📌 LSTM 모델 구현
📌 모델 결과 및 성능 분석
'🐍 파이썬 데이터 분석 프로젝트 > 🧠 EEG 뇌전증 분석 LSTM' 카테고리의 다른 글
| 🧠 EEG 뇌전증 분석 LSTM 05. Inference (0) | 2023.02.10 |
|---|---|
| 🧠 EEG 뇌전증 분석 LSTM 04. 결과 해석 (0) | 2023.02.09 |
| 🧠 EEG 뇌전증 분석 LSTM 03. 모델 정의 학습 (0) | 2023.02.09 |
| 🧠 EEG 뇌전증 분석 LSTM 02. 데이터 전처리 (0) | 2023.02.08 |