모바일은 화면을 돌려 가로화면으로 보시는 게 읽으시기 편할 수 있습니다. 돌려서 보시는 걸 추천드릴게요!!

새로운 데이터에 학습시킨 모델을 적용하기 위해서는 모델이 학습한 파라미터들을 기억하고 있어야 합니다. 이렇게 기억한 파라미터를 모델에 적용시켜 새로운 데이터의 calss를 예측하는 과정을 inference 라고 하는데, 이번 포스팅에서는 파이토치에서 이를 구현하는 과정을 다루도록 하겠습니다.
🏆 01. Inference를 위한 파라미터 파일 생성
🚩 파이토치 홈페이지의 공식 튜토리얼을 참고했습니다.
# 파라미터 저장 경로 설정
PATH_param = "C:\\Users\\mingu\\Desktop\\state_dict_model.pt"
# 파라미터 저장
torch.save(net.state_dict(), PATH_param)
# 파라미터 로드
net.load_state_dict(torch.load(PATH_param))
net.eval()>>
myRNN(
(features): Sequential(
(0): LSTM(15, 40, num_layers=2, batch_first=True, dropout=0.3)
)
(classifier): Sequential(
(0): Linear(in_features=40, out_features=20, bias=True)
(1): Linear(in_features=20, out_features=40, bias=True)
(2): Linear(in_features=40, out_features=20, bias=True)
(3): Linear(in_features=20, out_features=40, bias=True)
(4): ReLU(inplace=True)
(5): Linear(in_features=40, out_features=40, bias=True)
(6): ReLU(inplace=True)
(7): Dropout(p=0.3, inplace=False)
)
(output): Linear(in_features=40, out_features=3, bias=True)
)
# 업데이트된 파라미터 확인
net.state_dict()>>
OrderedDict([('features.0.weight_ih_l0',
tensor([[ 0.3825, 0.1696, 0.3888, ..., -0.0149, -0.2796, -1.0081],
[ 1.0355, 0.5075, 0.2560, ..., 0.2613, 0.3488, -0.2009],
[-0.4147, -0.5194, -0.4410, ..., -0.0834, 0.1688, 0.4171],
...,
[-0.6725, -0.4227, -0.0128, ..., -0.2711, -0.3587, -0.4195],
[-0.1928, -0.1214, 0.5168, ..., 0.1447, -0.2058, -0.0991],
[ 0.2795, 0.3319, 0.5523, ..., 0.0381, 0.1327, 0.0728]])),
('features.0.weight_hh_l0',
tensor([[ 0.5270, -0.2079, -0.4816, ..., -0.3560, 0.3740, 0.4470],
[-0.0881, -0.4017, 0.0637, ..., -1.4737, -1.3834, 1.5079],
[-0.3759, -0.4179, -0.2526, ..., -0.3713, 0.2377, -1.0464],
...,
[-0.5668, -0.5449, -0.3781, ..., -0.5061, 0.1073, -0.1213],
[-0.3803, -0.8716, -0.6513, ..., 0.5136, 0.0681, -0.7724],
[ 0.4183, 0.3132, -0.1342, ..., -0.4445, 0.0959, -1.0603]])),
...
('classifier.5.bias',
tensor([-0.1308, 0.1030, 0.1267, -0.0666, -0.0613, 0.4103, 0.0479, 0.0998,
-0.1504, 0.0691, 0.1012, -0.1428, 0.0597, 0.1899, 0.3041, -0.0564,
0.5632, 0.1733, 0.1954, -0.1826, -0.0478, 0.0654, 0.1379, 0.1210,
0.1259, -0.0603, -0.0402, -0.0956, 0.1471, 0.0671, 0.1954, -0.0753,
-0.0775, 0.4593, 0.1338, -0.0759, -0.0193, 0.1067, -0.1851, -0.0682])),
('output.weight',
tensor([[-0.0262, 0.0865, -1.8039, 0.0301, 0.0514, -0.8965, 0.0246, 0.1147,
0.0086, -0.1052, -0.1428, -0.0409, 0.0292, -0.3032, -1.3187, 0.1442,
-1.0137, -1.1594, -1.7114, 0.0856, -0.1952, -0.0184, -0.2582, -0.1644,
0.1112, 0.0126, -0.2563, 0.0422, 0.1493, -0.1287, 0.0607, 0.1801,
-0.1948, -0.9137, 0.1132, 0.1622, -0.1229, -2.1485, -0.0545, 0.0386],
[-0.1947, 0.0651, 0.0423, -0.1845, -0.1900, 0.1111, -0.1264, 0.1236,
0.0064, -0.1247, 0.1122, -0.0478, 0.0266, 0.0879, 0.1201, -0.1136,
-0.0439, 0.0650, 0.1954, -0.0810, -0.1865, -0.0361, 0.1091, -0.0765,
0.1065, -0.2159, 0.1534, -0.1994, 0.1131, -0.0384, 0.0438, -0.0103,
-0.1673, 0.1535, 0.1001, -0.0535, 0.0366, 0.0394, -0.1038, -0.1685],
[-0.1898, -0.2121, 0.1602, 0.0234, 0.0502, 0.0968, -0.1677, -0.1416,
0.0380, 0.0650, -0.1265, 0.0473, -0.2996, -0.0904, 0.1072, 0.1383,
-0.0398, 0.2001, 0.0646, -0.0855, 0.0305, -0.2599, -0.2001, 0.1095,
-0.1752, -0.0176, -0.1028, 0.0166, -0.0825, 0.1193, -0.1915, 0.1822,
0.0942, 0.1704, -0.1392, 0.1223, 0.0286, 0.0680, -0.0816, 0.0403]])),
('output.bias', tensor([-1.2432, -0.0050, 0.0236]))])
🏆 02. Train Set / Validation Set 나누기
🚩 Inference를 위해서 데이터를 다시 Train Set 과 Validation Set 으로 나눠주겠습니다.
🚩 랜덤하게 나눠주기 때문에, 학습할 때와 다른 set 결과가 나오게 될 것입니다.
import torch
import numpy as np
import random
import matplotlib.pyplot as plt
import pandas as pd
from torch import nn
from sklearn.preprocessing import StandardScaler, MinMaxScaler
standard = StandardScaler()
minmax = MinMaxScaler()
import torch, gc
gc.collect()
torch.cuda.empty_cache()d = pd.read_csv('C:\\Users\\mingu\\Desktop\\data.csv')
d = d.drop('column_a',axis = 1)
d['y'] = d['y']-1
d.loc[(d['y'] != 0) & (d['y'] != 1) , 'y'] = 2
# label의 비율을 고려하여 train set / validation set 생성
d_0 = d[d['y']==0].copy()
d_0_train = d_0[:1800].copy()
d_0_test = d_0[1800:].copy()
d_1 = d[d['y']==1].copy()
d_1_train = d_1[:1800].copy()
d_1_test = d_1[1800:].copy()
d_2 = d[d['y']==2].copy()
d_2_train = d_2[:5400].copy()
d_2_test = d_2[5400:].copy()
train = pd.concat([d_0_train, d_1_train, d_2_train])
test = pd.concat([d_0_test, d_1_test, d_2_test])
train_x = train.drop(['y'], axis = 1).copy()
train_y = train['y'].copy()
test_x = test.drop(['y'], axis = 1).copy()
test_y = test['y'].copy()
# EEG 신호의 noise를 고려해주기 위해 정규화 진행
from sklearn.preprocessing import StandardScaler
standard = StandardScaler()
train_x_st = standard.fit_transform(train_x)
test_x_st = standard.fit_transform(test_x)
🏆 03. 모델 가져오기
🚩 당연히 학습 과정에서 만든 모델을 그대로 가져와서 정의합니다.
class myRNN(torch.nn.Module):
def __init__(self, input_size, hidden_size, num_layers, out_size):
super().__init__()
self.features = torch.nn.Sequential(
torch.nn.LSTM(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=False,
dropout=0.3)
)
self.classifier = torch.nn.Sequential(
torch.nn.Linear(hidden_size, 20),
torch.nn.Linear(20,40),
torch.nn.Linear(40,20),
torch.nn.Linear(20, hidden_size),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(hidden_size, hidden_size),
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(0.3),
)
self.output = torch.nn.Linear(hidden_size, out_size)
def forward(self, x):
features, _ = self.features(x)
output = self.classifier(features)
output = self.output(output)
return output
net = myRNN(15,40,2,3)
net.to(device)>>
myRNN(
(features): Sequential(
(0): LSTM(15, 40, num_layers=2, batch_first=True, dropout=0.3)
)
(classifier): Sequential(
(0): Linear(in_features=40, out_features=20, bias=True)
(1): Linear(in_features=20, out_features=40, bias=True)
(2): Linear(in_features=40, out_features=20, bias=True)
(3): Linear(in_features=20, out_features=40, bias=True)
(4): ReLU(inplace=True)
(5): Linear(in_features=40, out_features=40, bias=True)
(6): ReLU(inplace=True)
(7): Dropout(p=0.3, inplace=False)
)
(output): Linear(in_features=40, out_features=3, bias=True)
)
🏆 04. 파라미터 업로드
🚩 앞선 단계 (01.Inference를 위한 파라미터 파일 생성) 에서 만든 파라미터 파일의 경로에서 파라미터를 가져옵니다.
# 가져올 경로 설정
PATH_param = "C:\\Users\\mingu\\Desktop\\state_dict_model.pt"
# 로드
net.load_state_dict(torch.load(PATH_param))
net.eval()>>
myRNN(
(features): Sequential(
(0): LSTM(15, 40, num_layers=2, batch_first=True, dropout=0.3)
)
(classifier): Sequential(
(0): Linear(in_features=40, out_features=20, bias=True)
(1): Linear(in_features=20, out_features=40, bias=True)
(2): Linear(in_features=40, out_features=20, bias=True)
(3): Linear(in_features=20, out_features=40, bias=True)
(4): ReLU(inplace=True)
(5): Linear(in_features=40, out_features=40, bias=True)
(6): ReLU(inplace=True)
(7): Dropout(p=0.3, inplace=False)
)
(output): Linear(in_features=40, out_features=3, bias=True)
)
🏆 05. Inference 진행
🚩 Inference를 위해 Validation set에서 각 label에 해당하는 데이터를 가져오겠습니다.
📝 class = 0
# label = 0인 Validation set의 sample
test_x.iloc[0] # 원본 데이터에서의 index : 9003
test_x.iloc[495] # 원본 데이터에서의 index : 11487>>
x1 98
x2 107
x3 121
x4 143
x5 166
...
x174 95
x175 107
x176 111
x177 110
x178 119
Name: 11487, Length: 178, dtype: int64
📝 class = 1
# label = 1인 Validation set의 sample
test_x.iloc[504] # 원본 데이터에서의 index : 8872
test_x.iloc[996] # 원본 데이터에서의 index : 11484>>
x1 -18
x2 -12
x3 -5
x4 -4
x5 -3
..
x174 -41
x175 -30
x176 -26
x177 -17
x178 -17
Name: 11484, Length: 178, dtype: int64
📝 class = 2
# label = 2인 Validation set의 sample
test_x.iloc[1003] # 원본 데이터에서의 index : 9055
test_x.iloc[2496] # 원본 데이터에서의 index : 11494>>
x1 -39
x2 -16
x3 -13
x4 -14
x5 -68
..
x174 -66
x175 -49
x176 -34
x177 -31
x178 -52
Name: 11494, Length: 178, dtype: int64
모델과 파라미터도 가져왔고, 데이터도 가져왔으니 이제 정말 Inference를 진행할 순서입니다.
📝 Inference 진행
▪ 언급한 각각의 sample에 대해 inference를 진행합니다.
▪ 원본 데이터를 전처리한 validation set이므로 원본 데이터의 인덱스가 아닌 validation set의 인덱스를 입력해줍니다.
▪ inference에 사용한 class별 인덱스는 아래와 같습니다.
- label 0 : 0, 495
- label 1 : 504, 996
- label 2 : 1003, 2496
▪ 랜덤한 input을 위해 randint 함수로 랜덤한 정수를 만들고, 120의 길이만큼 데이터를 가져옵니다.
▪ 모델은 feature를 랜덤하게 가져오기에 첫 시행에서 잘못 예측해도 다음 예측에서는 대부분 옳은 예측을 했습니다.
- 파라미터를 업로드하고, 가져온 sample data를 view함수를 통해 myRNN의 input 형태에 맞게 shape 조절
- .eval( ) 함수를 호출하여 평가단계에서 진행하도록 설정합니다.
- softmax 함수와 argmax 함수를 통해 가장 큰 값을 가지는 인덱스를 구해서 result를 출력합니다.
a = torch.tensor(test_x_st[1003])
r2 = random.randint(0,40)
a = a[r2:r2+120]
device = "cuda" if torch.cuda.is_available() else "cpu"
net = net.to(device)
model_state_dict = torch.load(PATH_param, map_location=device)
net.load_state_dict(model_state_dict)
net.eval()
X = a.view(1,8,15).to(torch.float32)
with torch.no_grad():
y_vd_pred = net(X.to(device))
y_vd_pred = y_vd_pred[:,-1,:]
result = torch.argmax(y_vd_pred.cpu().softmax(1),dim=1)
print(result)
🏆 06. Inference 결과 분석
학습결과 전반적으로 높은 accuracy를 보여주었기에 vallidation data를 input으로 입력했을 때 결과 역시 대부분의 경우에도 제대로 예측하였습니다. 그럼에도 제대로 파악하지 못하는 몇가지 경우(test_x_st[1003], label = 2)를 분석하기 위해 신호의 파형을 출력해 보았습니다. test_x_st[1003]의 경우에는 원래 label이 2지만, 실제 inference를 돌려보면 1로 예측하는 경우가 존재했습니다. label이 2인 다른 샘플을 예측할 때에는 제대로 예측을 하는 것으로 보아, 이는 아래의 그림에서 보듯이 label이 1인 [996]과 유사한 패턴이 [1003]의 파형에 존재하기 때문으로 사료됩니다. 랜덤한 범위에서 L개의 데이터를 추출하도록 설계해 두었기 때문에, 그 유사한 부분을 함께 가져오면서 잘못된 예측을 할 가능성이 생긴 것 같습니다. 어쩌면 label 2를 결정하는 부분이 파형에 존재하는 자잘한 변화들 때문이라 생각했습니다만, [1003]의 파형은 [2496]과는 다르게 그 자잘함이 눈에 띄지는 않습니다. 하지만, inference를 다시 진행하여 새로운 L의 범위를 랜덤하게 받아오면 제대로 예측하는 것을 확인할 수 있었습니다.
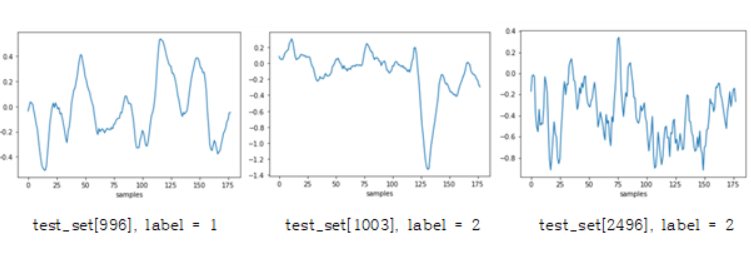
위에서의 예 뿐만 아니라 서로 다른 label을 가지고 있으나 유사한 부분이 신호에 존재하는 경우에는 예측이 틀리는 경우가 존재하였습니다. 이는 아무래도 랜덤하게 추출하는 과정에서 신호의 이어짐이 끊긴 이유도 있을 테지만, 기장 큰 이유는 사람이 신호의 파형만을 보고 EEG 신호의 노이즈를 판별하여 분석해내기에는 어려움이 따르기 때문이라고 생각합니다. 반면 같은 이유로 inference를 할때 랜덤한 구간 L을 설정해주기 때문에 잘못 예측한 경우 역시 inference를 다시 진행해보면 대다수가 원래의 label과 일치하는 것을 확인할 수 있습니다.
무의식적인 뒤척거림이나 눈 움직임에 의해 신호에 큰 변화가 일어나는 EEG 신호를 사용했기 때문에 이를 어느정도 보정해주기 위한 적절한 표준화 방법이 필요했습니다. 따라서 신호의 noise를 제거해주기 위해 moving average와 MinMaxScaler, StandardScaler를 각각 적용해보았는데 StandardScaler의 경우에 가장 좋은 결과를 나타냈기 때문에 이 method를 선택해서 학습을 진행했습니다.
모델의 일반성을 확인해보기 위해서 다른 EEG data(945 rows, 1149 columns)를 적용해서 classification을 진행하였으나, 이 데이터에 대해서는 좋은 결과를 얻지 못했습니다. 우선적으로 해당 데이터의 7개의 label들에 대한 분포가 고르지 않았습니다. 또한 본 프로젝트에 사용한 데이터(11500 rows, 179 columns)에 비해 column의 수는 많지만, 그 수많은 EEG 신호에 대한 노이즈를 잡아 결과를 얻기에는 object의 수가 너무 적었기 때문이라고 생각합니다.
결론적으로 EEG 신호처럼 노이즈가 많은 데이터를 분석하기 위해서는 이를 잘 설명해줄 수 있을 만한 충분한 수의 데이터와 적절한 scaler 방법이 필요하다고 생각합니다. 또한 앞서 말했듯 사람이 이러한 노이즈를 잡아내고 패턴을 분석해서 그에 해당하는 인사이트를 도출하기는 너무 어렵기 때문에 EEG 신호와 같은 의학적 분야에 인공지능이 꼭 필요할 것이라고 결론을 내렸습니다.
🚩 이렇게 최종 Infernece 과정까지 정리하면서 본 프로젝트의 요약을 마치겠습니다!! 프로젝트 진행할 때 처음 배우는 인공지능이다 보니 삽질도 많이 하고, 모델 구현을 위해 파라미터를 계속 변경하면서 소비한 시간이 정말 많았습니다. 변수 하나를 건드려서 모델의 성능을 엄청나게 끌어올릴 수 있다는 점도 굉장히 신기하기도, 허무하기도 했고 말이죠🙂. 이렇게 정리하고 보니 프로젝트 진행 과정이 하나하나 기억나는데요, 결과적으로는 나름대로 만족할 만한 멋있는 프로젝트를 했던 것 같습니다. 이렇게 얻은 경험을 가지고 무엇이든 꾸준히, 그리고 열심히 해보아야겠다고 다짐해봅니다.
'🐍 파이썬 데이터 분석 프로젝트 > 🧠 EEG 뇌전증 분석 LSTM' 카테고리의 다른 글
| 🧠 EEG 뇌전증 분석 LSTM 04. 결과 해석 (0) | 2023.02.09 |
|---|---|
| 🧠 EEG 뇌전증 분석 LSTM 03. 모델 정의 학습 (0) | 2023.02.09 |
| 🧠 EEG 뇌전증 분석 LSTM 02. 데이터 전처리 (0) | 2023.02.08 |
| 🧠 EEG 뇌전증 분석 LSTM 01. readme (0) | 2023.02.08 |