모바일은 화면을 돌려 가로화면으로 보시는 게 읽으시기 편할 수 있습니다. 돌려서 보시는 걸 추천드릴게요!!

🚩 저번 포스팅에서는 데이터를 전처리하는 과정을 다루었습니다. 예측할 label은 0,1,2 의 3가지 종류입니다.
🚩 이번 포스팅에서는 필요한 부분을 가져오는 data_iter 함수 와 LSTM 모델 을 정의하고 학습하는 부분까지 다루겠습니다.
만들고자 하는 모델은 사용자의 EEG sequence를 넣었을때 그 사람이 어떤 상태(간질발작-0, 종양-1, 건강-2)에 놓여있는지를 파악하는 모델입니다. 측정을 위한 전극의 위치나 개수를 고려하여 이미 한번 셔플한 데이터였지만, 보다 랜덤한 표본을 통해 모델을 학습시키기 위해서 임의의 랜덤한 부분에서 120개의 신호를 가져올 수 있도록 data_iter와 모델을 설계하였습니다.
🏆 1. Data_Iter 함수 정의
사용자의 전극 부착 위치나 개수에 따라 신호의 개수가 달라질 수 있기에, 임의의 L개 신호를 가져오도록 구현하였습니다.
# Data_iter 함수 정의
def data_iter(batch_size, X, y, L):
# 무작위성을 위해 X의 인덱스를 받아 shuffle
num_examples = len(X)
indices = list(range(num_examples))
random.shuffle(indices)
# 학습을 위해 데이터를 batch_size 크기로 나눠서 받음
# 전체 데이터를 한바퀴 순회함 : 1 epoch
# 각 feature에서 임의의 L개만큼 가져오기 위해
# randint를 통해 랜덤하게 L개를 가져올수 있도록 함
# feature tensor와 label tensor를 zero tensor로 초기화하고,
# L개의 해당하는 label을 받아올 수 있도록 함
# batch_indices에 랜덤하게 섞은 indices를 슬라이싱해서 인덱스를 받아줌
# 만약 i + batch_size가 총 데이터의 길이보다 길어지면 마지막 데이터까지만 받아옴
# ex) 데이터 수 = 314, i = 310, batch_size = 10이면
# 마지막 인덱스 310:314 까지만 슬라이싱해서 받음
# yield 로 batch_size만큼의 X와 y를 반환 - generator 형식
for i in range(0, num_examples, batch_size):
r1 = random.randint(0,40)
features = torch.zeros(batch_size,L)
labels = torch.zeros(batch_size,)
batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])
features = torch.tensor(np.array(train_x_st[batch_indices,r1:r1+L]))
labels = torch.tensor(np.array(train_y.iloc[batch_indices])).to(torch.float32)
yield features, labels
구현한 data_iter 함수의 작동을 확인하기 위해 EEG 신호의 파형을 출력해 보았습니다.
제대로 작동할 경우 L개의 sample에 대한 파형을 출력해 줄 것입니다.
L = 100
for X_tr, y_tr in data_iter(10,train_x_st,train_y,L):
print(X_tr.shape)
print(y_tr.shape)
for n in range(1):
plt.plot(X_tr[n])
plt.title(y_tr[n])
plt.xlabel('samples')
plt.show()
break
함수의 작동을 확인하였고, 시험삼아 test set에 대해서도 검증해보았습니다.
plt.plot(test_x_st[2497])
plt.xlabel('samples')
plt.show()
🏆 2. 모델 정의
🚩 데이터를 호출하는 함수도 정의했으니 이제는 학습을 위한 모델을 정의해줄 차례입니다.
▪ myRNN 이라는 이름을 가진 클래스를 정의하였습니다.
▪ LSTM의 학습 방법을 가지며, batch_size 를 첫번째 인수로 받아오고 bidirectinal은 False로 설정하였습니다.
▪ LSTM의 dropout은 0.3 으로 설정하여 40개의 hidden layer에 대해서 적절한 dropout을 하도록 설정하였습니다.
▪ LSTM 과정을 거치면 forward 함수 에서 정의한 순서에 따라 classifier, output 연산이 순서대로 진행됩니다.
▪ 몇번의 Linear 연산을 거친 후에 ReLU 를 통해서 비선형성을 파악하고 보완할 수 있도록 구현했습니다.
▪ classifier 연산 에 있어서도 dropout = 0.3으로 정의하였습니다.
▪ 마지막으로 Linear 모델 을 거쳐 최종 output 이 출력되도록 했습니다.
class myRNN(torch.nn.Module):
def __init__(self, input_size, hidden_size, num_layers, out_size):
super().__init__()
self.features = torch.nn.Sequential(
torch.nn.LSTM(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=False,
dropout=0.3)
)
self.classifier = torch.nn.Sequential(
torch.nn.Linear(hidden_size, 20),
torch.nn.Linear(20,40),
torch.nn.Linear(40,20),
torch.nn.Linear(20, hidden_size),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(hidden_size, hidden_size),
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(0.3),
)
self.output = torch.nn.Linear(hidden_size, out_size)
def forward(self, x):
features, _ = self.features(x)
output = self.classifier(features)
output = self.output(output)
return output
# 사용을 위해 myRNN의 이름을 net으로 지정
# input_size = 15, hidden_size = 40, num_layer = 2, output_layer = 3으로 지정
# label의 경우가 3개이기 때문에 output을 3으로 지정
net = myRNN(15,40,2,3)
net.to(device)>>
myRNN(
(features): Sequential(
(0): LSTM(15, 40, num_layers=2, batch_first=True, dropout=0.3)
)
(classifier): Sequential(
(0): Linear(in_features=40, out_features=20, bias=True)
(1): Linear(in_features=20, out_features=40, bias=True)
(2): Linear(in_features=40, out_features=20, bias=True)
(3): Linear(in_features=20, out_features=40, bias=True)
(4): ReLU(inplace=True)
(5): Linear(in_features=40, out_features=40, bias=True)
(6): ReLU(inplace=True)
(7): Dropout(p=0.3, inplace=False)
)
(output): Linear(in_features=40, out_features=3, bias=True)
)
🏆 3. Loss Function / Optimizer 정의
🚩 모델에서 사용할 손실함수와 최적화함수를 정의해주겠습니다.
▪ learning_rate = 0.001 로 설정하였습니다.
▪ loss function으로 CrossEntropyLoss 를 사용하였습니다.
▪ torch.nn.init.uniform_ 을 사용해 가중치가 균일한 분포를 따르도록 초기화 했습니다.
▪ Optimization algorithm으로는 Adam 을 사용하여 sgd와 momentum을 모두 고려할 수 있도록 생성했습니다.
▪ 이때 그래디언트 제곱의 실행 평균을 계산하는 계수인 betas는 default 값인 (0.9, 0.999)로 설정했습니다.
▪ 각 epoch의 accuracy를 epoch_tr_accuracy, epoch_vd_accuracy 리스트에 저장해 accuracy 시각화를 진행하겠습니다.
learning_rate = 0.001
tensor = torch.empty(3)
loss = nn.CrossEntropyLoss(weight=torch.nn.init.uniform_(tensor),reduction='mean')
alg = torch.optim.Adam(net.parameters(), lr = learning_rate, betas=(0.9, 0.999))
epoch_tr_accuracy = []
epoch_vd_accuracy = []
🏆 4. 모델 학습하기
🚩 이제 정의한 hyperparameter를 가지고 학습을 진행하겠습니다.
learning_rate = 0.001
eval_interval = 1
num_epochs = 3000
batch_size = 400
L = 120
for epoch in range(num_epochs):
l_train = []
i = 0
Ncorrect=0
N=0
net.train()
# data_iter함수를 호출하여 train feature와 train label을 가져옴
# 정의해준 L이 120이기 때문에 .view 함수를 통해 15개씩 8 묶음으로 묶어서 학습 진행
# myRNN에 feature를 넣어줌으로써 학습 진행
# 예측값 y_tr_pred 생성
# y_tr_pred와 실제 label 값을 비교하여 loss 계산
# 이후 backpropagation과 gradient 초기화를 반복해 모델의 학습 진행
# argmax 함수를 통해 모델의 출력 output 3개 중에서 가장 큰 값의 인덱스를 받아
# softmax 연산을 진행
for X_tr, y_tr in data_iter(batch_size, train_x_st, train_y,L):
X = X_tr.view(len(X_tr),8,15).to(torch.float32)
y_tr_pred = net(X.to(device))
y_tr_pred = y_tr_pred[:,-1,:]
l=loss(y_tr_pred.cpu(),y_tr.type(torch.LongTensor))
l.backward()
alg.step()
alg.zero_grad()
Ncorrect += torch.sum(y_tr==torch.argmax(y_tr_pred.cpu().softmax(1),dim=1)).numpy()
N += len(X_tr)
i=i+1
# data_iter함수를 호출하여 validation feature와 validation label을 가져옴
# 학습에서 예측이 맞은 개수 Ncorrect를 전체 개수 N으로 나눠 training accuracy를 얻음
# net.eval() 함수를 호출하여 평가 단계에서만 코드를 진행
# 상기 학습과정과 동일하게 진행되며, validation set에 대한 accuracy를 얻음
if epoch%eval_interval==0:
tr_accuracy = 100*Ncorrect/(N)
net.eval()
for X_vd, y_vd in data_iter(len(test_x_st), test_x_st, test_y,L):
X = X_vd.view(len(test_x_st),8,15).to(torch.float32)
with torch.no_grad():
y_vd_pred = net(X.to(device))
y_vd_pred = y_vd_pred[:,-1,:]
vd_accuracy = 100*torch.sum(
y_vd==torch.argmax(
y_vd_pred.cpu().softmax(1),dim=1))/(len(test_x_st))
if epoch%5==0:
print(f'epoch #{epoch}')
print(f'accuracy of train set: {tr_accuracy} %')
print(f'accuracy of valid set: {vd_accuracy} %')
epoch_tr_accuracy.append(tr_accuracy)
epoch_vd_accuracy.append(vd_accuracy)>>
epoch #0
accuracy of train set: 40.611111111111114 %
accuracy of valid set: 0.0 %
epoch #5
accuracy of train set: 78.24444444444444 %
accuracy of valid set: 69.08000183105469 %
epoch #10
accuracy of train set: 78.4 %
accuracy of valid set: 70.0 %
epoch #15
accuracy of train set: 78.77777777777777 %
accuracy of valid set: 70.5199966430664 %
...
epoch #2980
accuracy of train set: 93.43333333333334 %
accuracy of valid set: 98.63999938964844 %
epoch #2985
accuracy of train set: 94.11111111111111 %
accuracy of valid set: 97.95999908447266 %
epoch #2990
accuracy of train set: 94.04444444444445 %
accuracy of valid set: 97.4000015258789 %
epoch #2995
accuracy of train set: 93.14444444444445 %
accuracy of valid set: 97.87999725341797 %
🏆 5. Accuracy Curve
학습한 train set에 대한 accuracy와 validation set에 대한 accuracy를 시각화해 보았습니다.
validation set에 대한 모델의 성능이 train set에 비해 좋은 것을 확인 할 수 있었습니다.
# train accuracy와 validation accuracy 시각화
plt.figure(figsize = (20,12))
plt.plot(epoch_tr_accuracy)
plt.plot(epoch_vd_accuracy)
plt.legend(['train set','valid set'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()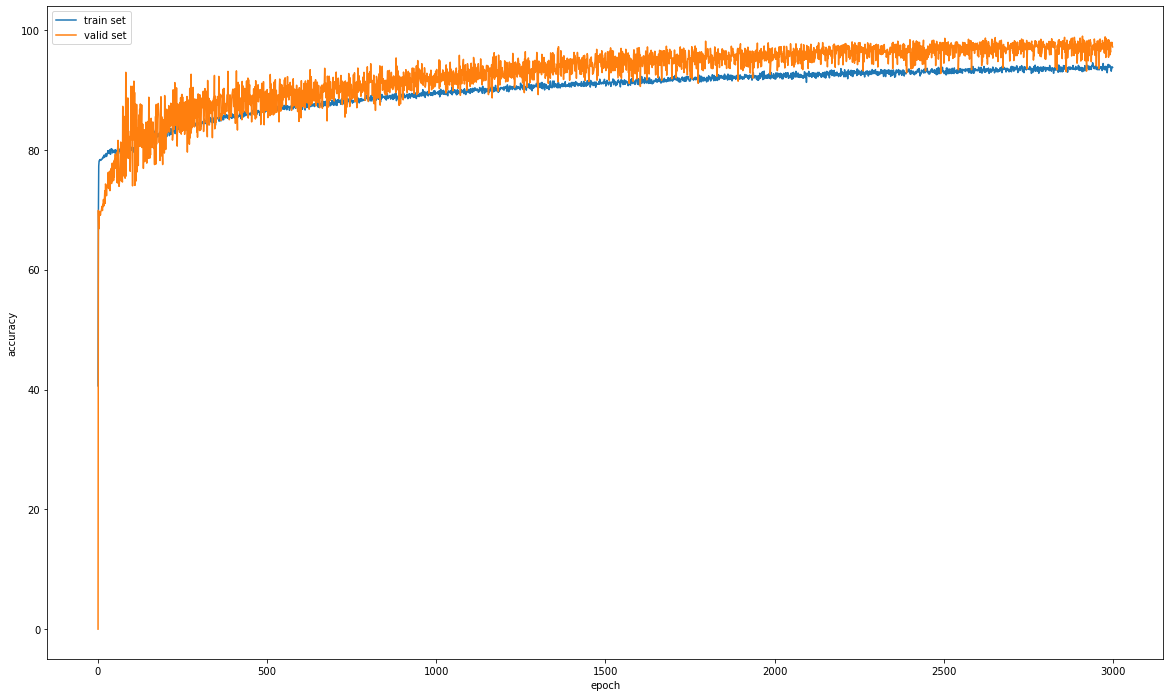
🚩 이번 포스팅을 통해서 인공지능의 전체적인 과정을 파악할 수 있습니다. 정리해보면 아래와 같습니다.
▪ 각 시행에 대해 전체 데이터에서 사용할 부분만을 원하는 크기만큼 추출하는 data_iter 함수 정의
▪ 데이터 학습과 테스트를 위한 AI 모델 생성 및 LSTM 내부 구조 확인
▪ 모델을 위한 손실 함수 및 최적화 함수 정의
▪ 모델 학습
▪ Accuracy Curve 시각화 및 확인
🚩 다음 포스팅에서는 confusion matrix를 통해 모델의 성능을 최종적으로 파악해 보겠습니다.
'🐍 파이썬 데이터 분석 프로젝트 > 🧠 EEG 뇌전증 분석 LSTM' 카테고리의 다른 글
| 🧠 EEG 뇌전증 분석 LSTM 05. Inference (0) | 2023.02.10 |
|---|---|
| 🧠 EEG 뇌전증 분석 LSTM 04. 결과 해석 (0) | 2023.02.09 |
| 🧠 EEG 뇌전증 분석 LSTM 02. 데이터 전처리 (0) | 2023.02.08 |
| 🧠 EEG 뇌전증 분석 LSTM 01. readme (0) | 2023.02.08 |